(Japanese/English)
人間の学習において,「質問に答える」ことは知能の重要な働きです.教科書を読んで知識を蓄え,テストで問題を解くように,人工知能も大量のテキストを読んで質問応答(QA)を行います.最近のChatGPTのような大規模言語モデル(LLM)は,過去の膨大な文章データから「次にくる言葉」を予測することで,まるで人間のようにこのQAタスクをこなし,会話することができます.
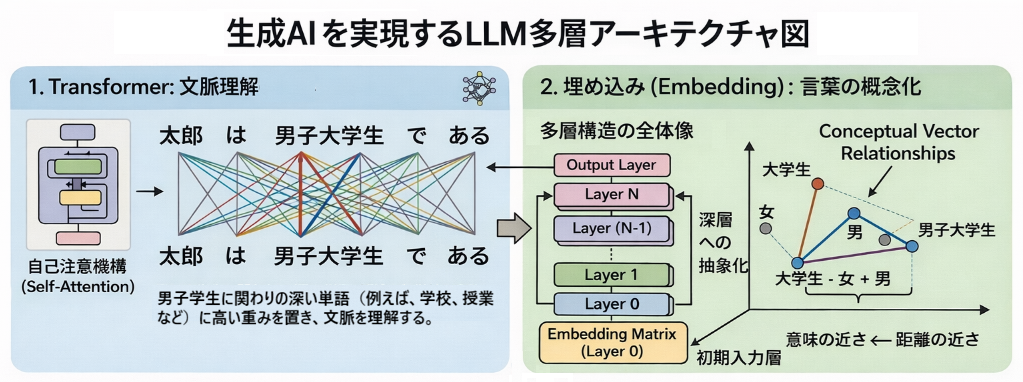
この知能を支えているのが**ディープラーニング(深層学習)**です.これは人間の脳神経を模した学習アルゴリズムで,画像や音声だけでなく,「言葉」が持つ複雑な意味や文脈までをもコンピュータが扱える形(特徴)として自動的に学習(表現学習)します.LLMは,この技術を使って言葉の意味のつながりを深く学習し,人間のような流暢な日本語を操ることができるのです.

兼岩研究室では,このディープラーニングなどの技術を使って,人工知能における知識表現と推論を研究しています. 特に,人間の「目」や「耳」にあたる画像・音声データではなく,思考の中核である「言葉」や「知識」という意味データそのものを対象にするのが特徴です.電気通信大学にはAIを扱う研究室は他にもありますが,人間の言葉の意味や論理の仕組みに深く切り込むのが研究室の特色です.
なぜ「言葉」や「知識」を使って学習するのは難しいのでしょうか?人間は「概念」同士の関係性を理解して答えを導きます(推論)が,AIにとって言葉は単なる記号の列になりがちです.画像データのように単純に数値化できないため,AIが「意味」を本当に理解して正しく推論するのは容易ではありません.私たちは,言葉の持つ**意味構造(知識の地図のようなもの)**に注目し,それを埋め込み(embedding)によってAIに言葉の概念を学習させることで,論理的に正しい推論ができる人工知能の実現を目指しています.
人工知能(AI)とは,人間のような知的な情報処理を可能にするコンピュータを開発する研究分野です.人間は,どのように知的な情報処理をしているのでしょうか?人間は,脳を使って,人や環境から知識を得て知的な活動を行っています.さらに,人間はこれまでにない新しい知識を生み出したり発見したりもします. 兼岩 憲教授は,(富士通(株)に三年勤務後,大学院を修了して),国立情報学研究所(文部科学省),情報通信研究機構(総務省)で,約十年間,人工知能における知識表現と推論の理論的研究に従事しており,その後,岩手大学に三年在籍し電気通信大学に赴任しました. 本研究室では,知的な情報処理に不可欠な「知識」を扱っています.人工知能を実現するために,その知識に関わる以下の基礎研究を行っています.
まず,「知識の獲得」は,外部から入手された情報から意味がある知識をどのようにコンピュータが見いだすかを研究します.次に「知識の表現」は,獲得した知識をコンピュータ上でどのように表すかを研究します.これはデータベースの研究にも関連します.最後に「知識からの推論・学習」は,獲得して表現された知識から新たな事実を導いたり,法則性やパターンを学んだりする仕組みを研究します. 人工知能を研究してみたい学生は,ぜひ兼岩研へ来てください!
ロボットやコンピュータが知識を活用するための基礎研究に知識表現と推論があります.それは,知識の意味をどのように構造的に表現するか,どう表現すれば知識から未知の情報を導くことができるか,を探求します.
事実(ファクト)「電通大の所在地は調布市です」
背景知識:「電通大は国立大学である」
「国立大学は大学である」
「調布市は東京都にある」
質問:「東京都にある大学は?」

人間は事実からこの質問に答えられます.しかし,コンピュータ(人工知能)は背景知識が無いと導くことができません.そのため,コンピュータが扱えるように事実と背景知識を記号で表し,さらにそれらから質問の答えを導く推論システムを研究しています.
人工知能は,どうやって人間の質問に答えることができるでしょうか?その答えとなる知識はどうやって学習するのでしょうか? 人間のように推論・学習するために,世の中に存在する膨大なデータを活用します.しかし整合性の取れた正しい推論を行うために,分野毎に特化した知識が必要になります.オントロジーは人間が現実世界に存在するものやことを概念化したもので,特定分野の知識を表現できます.それにより,人間が得意とする意志決定,予測,認識などをコンピュータが代わりに行うことを目指します.
例えば,データからどういう知識を学習するのでしょうか?
・りんご,猫,哺乳類や飛行機のようなカテゴリの性質を認識する
・テキスト情報から専門分野の用語を理解する
・Wikipediaなどに不足している情報を推定して補完する

これにより,例えば,「赤くて丸い果物は何か?」「肺呼吸するイルカは哺乳類か?」「糖尿病にはインスリン治療が効くのか?」などの概念知識を人工知能が学習して答えを推定できるようになります.
人間は現実世界の対象物(ものやこと)を概念化して,その意味を理解しています.概念(単語)の意味を知的なコンピュータが解釈するにはどうすればいいのでしょう? 一つの方法として,人間が解釈する概念には様々な性質や関係があり,それを体系化(オントロジー)します.
<例1>人間と教師の違い
人間(本質属性)は,存在する限り(死ぬまで)人間です.一方,教師(非本質属性)は,仕事を辞めたら教師でなくなります.
<例2>自動車と水の違い
自動車(sortal)は,その部分のタイヤやハンドルは自動車ではないです.一方,バケツの水から一部をコップですくっても水(non-sortal)です.
人間は文章を読んでその意味を理解し,逆に自分の意見を文章で表現します. コンピュータが文章を理解するには,どうすればいいでしょうか?そのためには文章の意味や内容を解析してその構造を表現する必要があります. そのように意味や内容を解読できるようになった表現から人工知能が推論・学習を行います.
セマンティックWebは,単なるテキストではなく意味や内容を扱える未来のWebを実現します.言い換えれば,従来のドキュメント中心のWebからコンピュータ(人工知能)が意味や内容を解読して知的なWebを目指します.
兼岩研究室では,セマンティックWebのためのデータベースとクエリ言語であるFROSTを公開しています.グラフ構造データに対するクエリ言語SPARQLの検索エンジンをJavaで独自開発しています. SQLがテーブル型データベースであったのに対して,SPARQLは(Webデータや柔軟な知識表現と相性のよい)グラフ構造型データベースでありNoSQLの1つと言えます. この研究の成果や新規性は実験結果の数字で表れる分シビアな世界でもあり,ひたすら性能の向上をめざせばいいので研究の方向性に悩む必要はありません.
コンピュータが結論を導くと「正しい」「間違い」の2択であり,エアコンなどを制御すると正確な数値(例えば,28度)でONとOFFを区別します.しかし,人間は,「全く正しい」「ほぼ正しい」「少し正しい」「どちらでもない」「少し間違い」「ほぼ間違い」「全く間違い」というようにあいまいで感覚的な判断をします.エアコンの制御も「暑い」「少し暑い」「ちょうどいい」「少し寒い」「寒い」といった感覚的な判断からONとOFFを決めます.
こうしたあいまいさは視覚的にも分かりやすいメンバーシップ関数を使って表します.例えば,自動車の速度を柔軟に表現できます.
高速(自動車)=0.4
中速(自動車)=0.1
低速(自動車)=0

このファジィ表現により,「自動車がやや高速ならば少し減速する」というような柔軟な推論や制御が可能となります.
ここ数年の人工知能の進歩により,生成AIはソフトウエア開発にも活用されています. 例えば,Webアプリやツールなどを,日本語文による人の指示だけでAIエージェントがプログラミングすることが可能になりつつあります.
本研究室では,生成AIを活用したプログラミング支援技術に関する研究を行っています. 具体的には,ゲームソフトウエアに対して, 機能の修正や拡張を効率的に行う手法の開発に取り組んでいます.
ゲーム「DARK HOUSE」の実装例(2026-04-12)
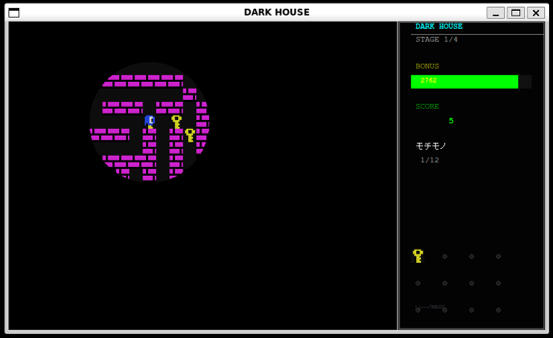
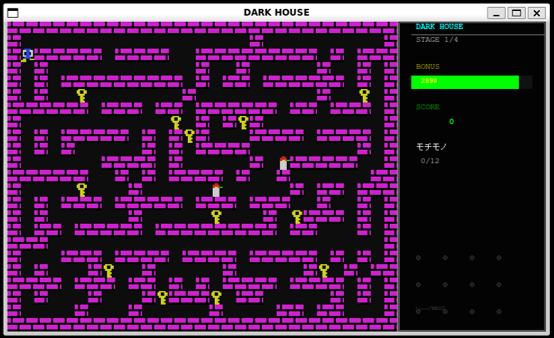
さらに,金融分野(株式取引など)においては, 企業の決算や財務情報を分析する際に, これまで研究室で取り組んできたオントロジーやUML図を用いて専門知識を構造化し, それを生成AIに組み込む研究も検討しています.
電気通信大学 大学院情報理工学研究科 情報・ネットワーク工学専攻
〒182-8585 東京都調布市調布ヶ丘1-5-1 兼岩 憲(kaneiwa(at)uec.ac.jp)